本指南提供了一系列寻找源代码的方法,包括使用代码托管平台的搜索功能、历史项目的访问、第三方下载平台的利用、以及直接获取源码的技巧。
目录
GitHub
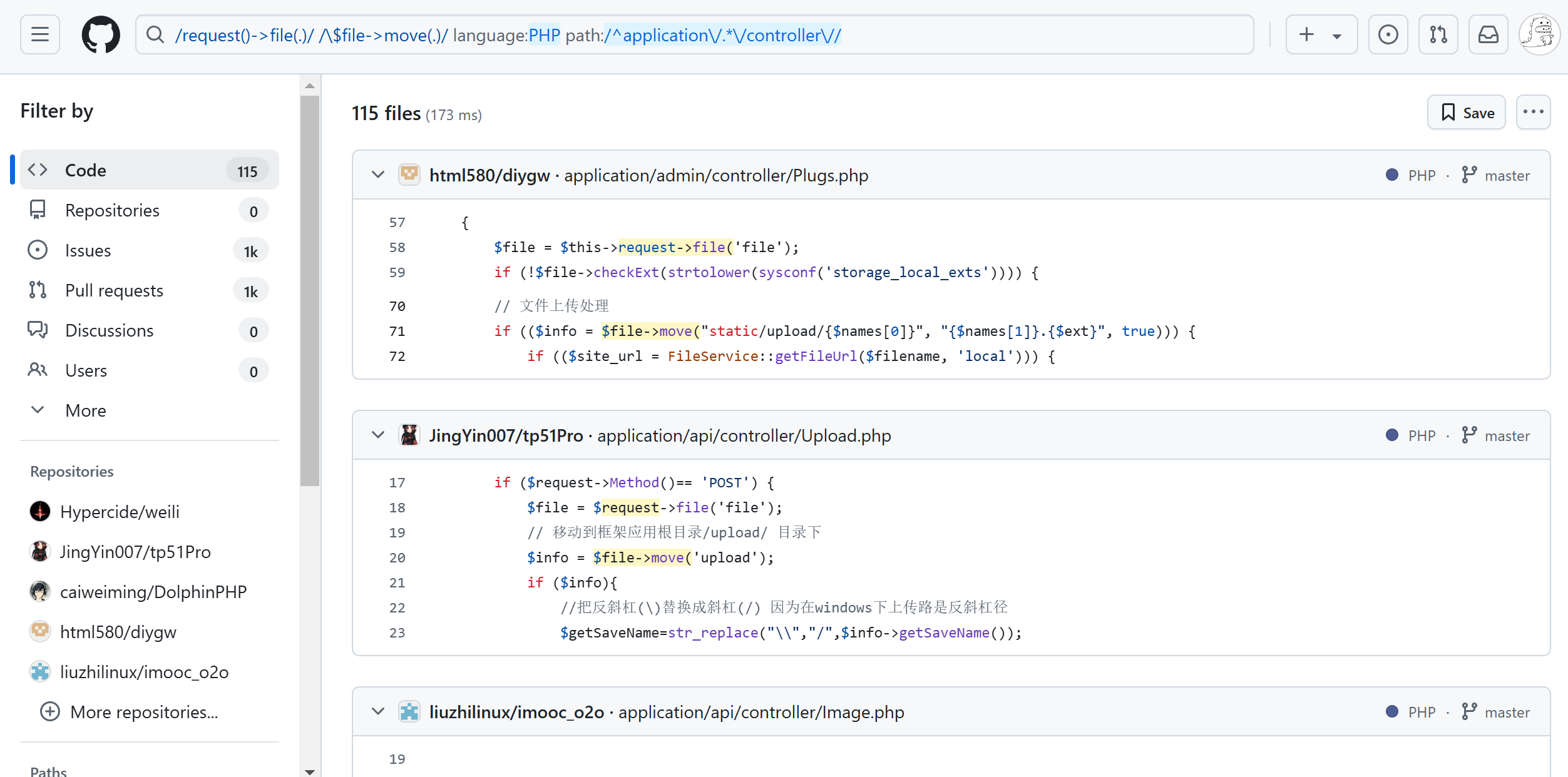
在 GitHub 上,可以通过关键字和搜索语法快速找到相关代码。例如,使用以下搜索字符串可能会找到潜在的 Thinkphp5 上传代码:
/request()->file(.)/ /\$file->move(.)/ language:PHP path:/^application\/.*\/controller\//
|
详细内容可以查看官方的 Github搜索语法介绍
Gitee
Gitee 是一个国内流行的代码托管平台,与 GitHub 类似。可以通过以下示例来搜索特定的 PHP 项目:
Wayback Machine
对于已下架或停止维护的项目,互联网档案馆的 Wayback Machine 是一个有用的工具。可以查看项目的历史页面,寻找代码库链接或片段。
网盘搜索
一些项目可能通过网盘分享,且链接会被爬虫抓取。使用网盘搜索引擎如 超能搜 可以找到源码。
利用漏洞信息
- CVE:CVE (Common Vulnerabilities and Exposures) 报告中通常包含源代码链接。
- Exploit-DB:该平台列出了已知漏洞的利用方式,部分漏洞会附带源代码。
- 漏洞利用文章:一些漏洞复现文章可能包含代码链接,甚至可以请作者分享一份代码。
开发者论坛/社区/用户群
开源项目通常有活跃的社区支持:
- 开源社区:如 Stack Overflow、Reddit、GitHub Discussions,用户可以在这些社区中寻求帮助。
- 社交媒体和论坛:一些项目会在社交媒体或论坛中创建讨论组,通过加入可以与项目开发者交流获取源码。
- 产品试用:一些付费项目可能提供试用,通过试用可能获取源码。
第三方下载平台
使用第三方平台下载存在风险,需注意安全防护,谨防木马。
官网和项目文档
很多项目的官网或文档页面会提供源代码的下载链接。开源软件官方网站通常有 “Application” 或 “Download” 按钮,直接指向代码库。
利用爬虫工具
如果项目官方网站提供了下载地址,可以编写爬虫自动抓取源代码地址。以下是一个获取所有版本代码的示例:
假设目标提供了链接 http://127.0.0.1/files/down/cms-1.4.2.zip
那么合理的猜测其他版本可能是0.0.0-1.4.2
import requests
import concurrent.futures
def generate_urls(base_url):
file_name = base_url.split('/')[-1]
base_url_prefix = base_url.replace(file_name, '')
base_url_suffix = file_name.split('-')[1]
urls = []
for major in range(2):
for minor in range(10):
for patch in range(10):
version = f"{major}.{minor}.{patch}"
url = f"{base_url_prefix}cms-{version}.zip"
urls.append(url)
return urls
def check_url(url):
try:
print(f"Checking URL: {url}")
response = requests.get(url, timeout=5)
if response.status_code == 200:
if b'\x50\x4b\x03\x04' in response.content:
print(f"Found: {url}")
return url
else:
print(f"Not a valid ZIP file: {url}")
else:
print(f"HTTP error {response.status_code} for {url}")
except requests.RequestException as e:
print(f"Error requesting {url}: {e}")
def main():
base_url = "http://127.0.0.1/files/down/cms-0.0.0.zip"
urls = generate_urls(base_url)
found_urls = []
with concurrent.futures.ThreadPoolExecutor(max_workers=20) as executor:
results = executor.map(check_url, urls)
for result in results:
if result:
found_urls.append(result)
print("\nSuccessfully fetched URLs:")
for url in found_urls:
print(url)
if __name__ == "__main__":
main()
|
通过资产测绘探测路径
对于不常见的项目,可以通过探测相同资产的备份文件和源代码包获取源码。常用方法是:
提取指纹 -> 寻找资产 -> 探测路径
示例路径:http://example.com/example.com.zip
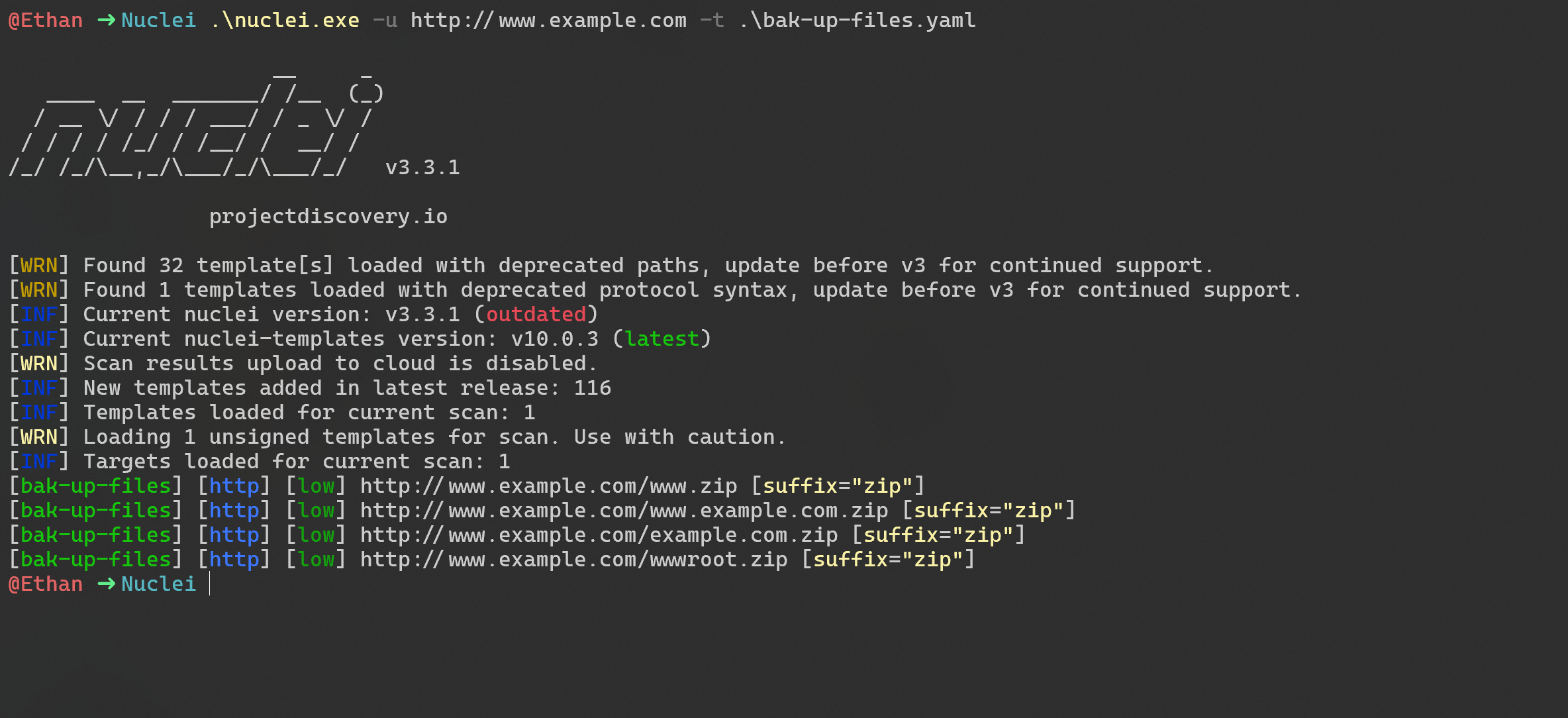
这是我通常用的Nuclei探测脚本:
id: bak-up-files
info:
name: Find Resource Code Of Target Template
author: Ethxu
description: |
wwwroot
{{FQDN}} # www.example.com
{{RDN}} # example.com
{{DN}} # example
{{TLD}} # com
{{SD}} # www
severity: low
tags: exposure,backup
requests:
- method: GET
path:
- "{{RootURL}}/{{DN}}.{{suffix}}"
- "{{RootURL}}/{{FQDN}}.{{suffix}}"
- "{{RootURL}}/{{TLD}}.{{suffix}}"
- "{{RootURL}}/{{SD}}.{{suffix}}"
- "{{RootURL}}/{{RDN}}.{{suffix}}"
- "{{RootURL}}/wwwroot.{{suffix}}"
payloads:
suffix:
- 'zip'
- 'rar'
- 'gz'
- 'tar.gz'
- '7z'
- 'bz2'
- 'tar.z'
max-size: 300
matchers-condition: and
matchers:
- type: binary
binary:
- "377ABCAF271C"
- "314159265359"
- "1f8b"
- "526172211A0700"
- "526172211A070100"
- "FD377A585A0000"
- "1F9D"
- "1FA0"
- "504B0304"
condition: or
part: body
- type: status
status:
- 200
|